
Reproducible Research: WorldMake.org
Open Peer Review: OpenReview.net
GitHub: davidsoergel
Twitter: @loraxorg
Science needs fixing.
Many recent reports that scientific results are not reproducible (Ioannidis, 2005-2014; RetractionWatch) make it all too easy too reach the cynical conclusion that nearly every reported result is wrong. Sam Ruhmkorff calls this the “global pessimistic meta-induction”, but argues that this level of cynicism is overly broad, when most individual experiences justify only a “local pessimistic meta-induction”, e.g. that the scientific results in a particular field or produced by certain researchers are probably wrong. Let us hope he is right that science as a whole is not doomed.
Note on vocabulary: many scientists make a distinction between "replication" (e.g., same experimental conditions) and "reproduction" (e.g., different conditions, same conclusion), but other scientists make the opposite distinction. Here we give up and use the terms interchangeably.
What is a scientific result?
Precision. In order to know whether a result has been reproduced, it is essential first to state very precisely what the result actually is. Frequently two papers make similar-sounding claims about the same general topic, leading readers to believe that a result has been confirmed--when in fact, upon closer examination, the claims are qualitatively and quantitatively different.
Abstraction. Related: authors very frequently make far broader claims than their specific findings justify--not only in the discussion, but even in the abstract and the title. Following on publication of some result, another paper may lend support to the same general claim on the basis of different specific findings. In such a case, the exact experiment was not reproduced, but the general conclusion may have become more credible through multiple lines of evidence. It would overstate the case to say it has been “reproduced”, since two experimental conditions are likely insufficient to prove a more general point even once. The more abstract the claim, the more diverse evidence is needed to establish it.
It is common to describe these things using ambiguous language, e.g. “we reproduced the results of Gryphon et al. 2009”. Which results, exactly? At what level of abstraction? To what extent were the experimental design, materials, and methods shared between the two studies?
Levels of reproduction and confirmation depth
The point of reproducing a study is to eliminate possible sources of error. However: if a reproduction is subject to the same sources of error present in the original study, then it clearly does not fulfill this purpose, and so may serve only to provide a false sense of security.
We must therefore ask: if the first paper to report a result contains an error, is there any pathway whereby that error might propagate to a second paper reporting the same result? People may say “multiple lines of evidence”, which of course sounds good, but was the underlying sample the same? Was the work done in the same lab? Was the same software used?
Robust results require different experimental conditions.
In fact the most convincing reproduction of a result is one in which every aspect of the protocol was different, but the result was the same--indicating that it is robust. Differences we may look for and celebrate include:
- Different data sources (e.g. samples)
- Different researchers
- Different laboratory
- Different hardware
- Different firmware (e.g. In sequencing machines -> affects error profile. In cameras -> affects color profile)
- Different software
- Different workflow system (?)
- Different thought process/experimental design (perhaps undermined by knowledge of prior paper).
Only at the final step--interpreting the results--is it essential that all parties agree on something, namely that the experimental design, data, and analysis in fact support the claimed conclusions. This is of course what peer review is intended to verify.
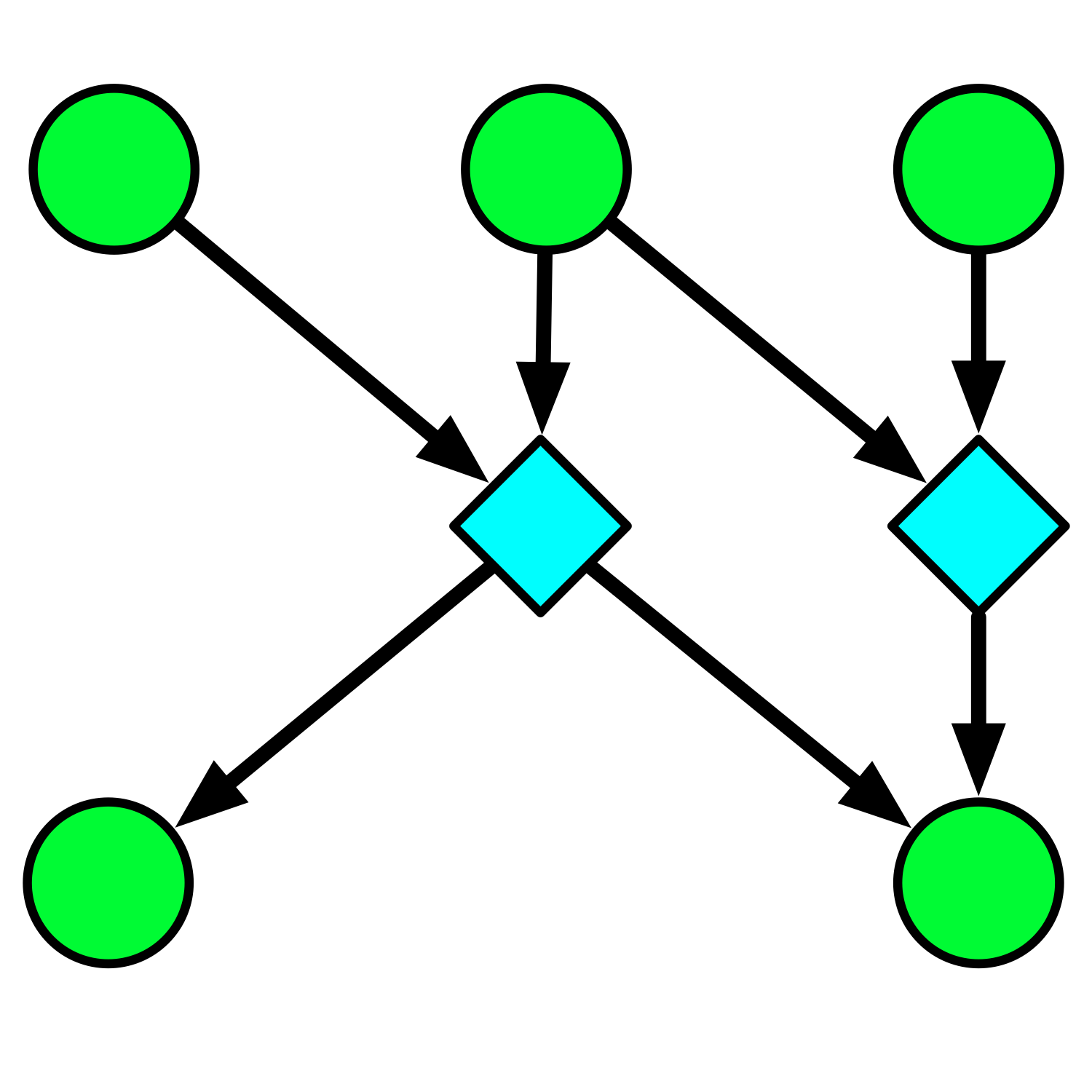
Drawing derivation networks allows measuring confirmation depth.
Any research project can be thought of as a series of derivations, starting from raw inputs, proceeding through intermediate results (e.g. processed samples, data files), and ultimately producing not only a final quantitative result but also interpretations, all encapsulated in a published work.
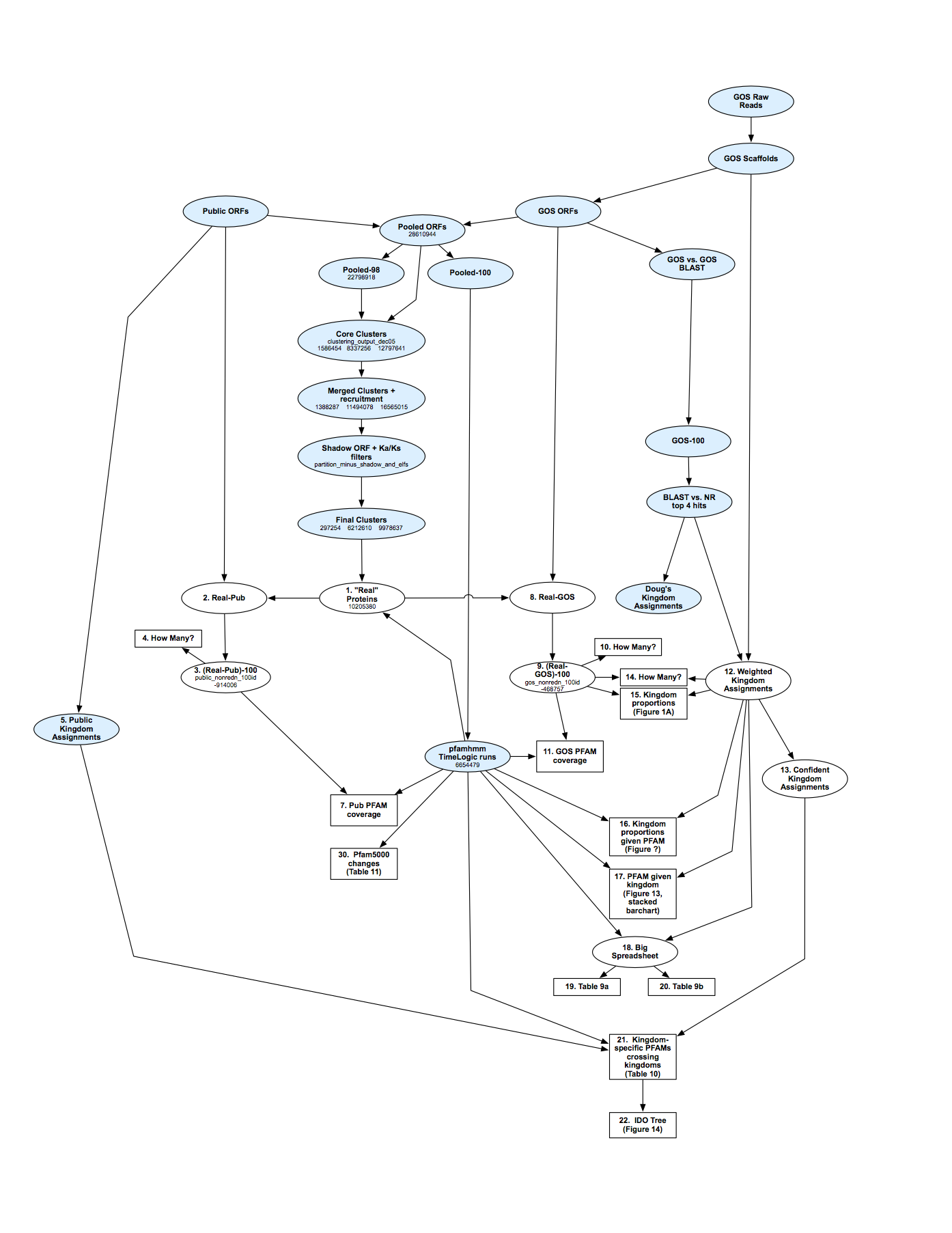
Figure 1. Any scientific result arises from a network of derivations, leading from raw inputs (e.g., measurements, source code), through intermediate results, to outputs. This example shows the computational portion of such a network (neglecting e.g. experimental design and sample collection, starting from raw sequencing reads in the upper right), which produced the results of Craig Venter's Global Ocean Survey project (Yooseph et al. 2007).
At whatever point in this series of derivations an error occurs, it renders useless all the work that came before--i.e., if there is a software bug late in the game, then all bets are off as to what was in the sample.
This suggests the concept of confirmation depth: given two papers with the same result, how many steps back from that result is the first commonality of materials or methods found? Conversely, how derived are the givens shared by the two papers?
Of course, a certain level of replication is required within a paper as well. Here the same principle applies: in biology, researchers speak of “biological replicates” (different samples) as more meaningful than “technical replicates” (repeated analyses from the same sample). Those are two points on a continuum of confirmation depth.
Peer review is the shallowest form of confirmation.
Peer review asks: given that the experiment has already been designed, the samples collected, the data analyzed, etc., does the conclusion make sense? That is, we ask peer reviewers to reproduce the thought process leading from the data to the qualitative conclusions (which is effectively the final step in the derivation), in order to confirm that the argument is cogent.
A particularly dedicated peer reviewer might recompute some result from provided data files, perhaps using the same software or the same methods. Doing so “peels” the confirmation away from the original result, and thereby increases the confirmation depth by one step.
Deeper confirmations give greater confidence.
Deeper confirmations may be performed by other researchers, peeling back the confirmation by any number of additional steps. Some may reanalyze the published data using different software or different statistical methods; others may request physical samples to be mailed for independent measurements, followed by analysis with different software; others may go so far as to collect entirely new samples and to analyze them by a completely different procedure. The deeper the confirmation, the more confidence we will have in the result. Conversely: the shallower any attempt that produces a failure to confirm, the less confidence we will have in either the original or the new result.
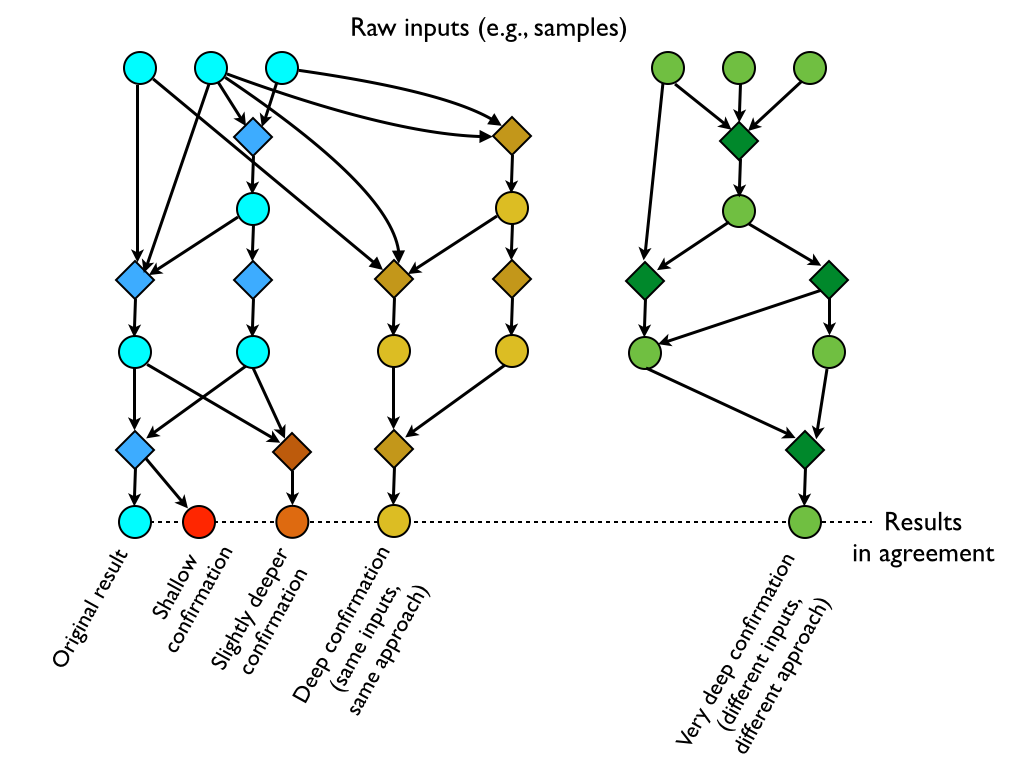
Figure 2. Attempts to reproduce a final result may start from intermediate results of the original project. The more diverged the chain of derivations, the fewer opportunities for error the two efforts have in common--and so, the more confidence we may have that the result was meaningfully reproduced.
Shallow commonalities trump deep differences as sources of error.
The idea of confirmation depth points out a real danger: a well-intentioned attempt to reproduce a result deeply--using different samples, processing them in a different lab, etc.--may nonetheless be undermined by late-stage sources of error. Using the same software (with the same bug), or using the same statistical method (with the same weakness), may spuriously produce the same result. Consequently, shallow commonalities should trump deep differences in reducing our trust in the outcome, unless we have extremely high confidence that the common elements cannot be a source of error.
Naturally we are happiest when we get the same result from a large number of experiments having nothing whatsoever in common--as is the case for our foundational beliefs about gravity, evolution, climate change, and so on.
Detailed materials and methods are essential to distinguish shallow from deep confirmations.
No confirmation is possible without extremely precise descriptions of materials and methods. The point is not that the reproducing lab should necessarily follow the original protocol exactly, as doing so would in fact reduce the confirmation depth; rather, the reproducing lab may wish to purposely follow a different procedure, or use reagents from different sources, in order to eliminate (or at least average over) possible sources of error. Perhaps-inadvertent commonalities between two protocols can only be known if they are both spelled out in meticulous detail. On the other hand, it is wise to perform confirmations progressively from shallow to deep. If even following the exact protocol with the exact same materials does not produce the same result, then there is no point in seeking a deeper confirmation-- at least, not of the specific finding.
A converse danger is that, the more deeply diverged two experiments are from one another, the less likely they are to produce results that are comparable at all. This is why it is necessary to state very precisely what claims are being made. Such claims may be made at multiple levels of generality, so that two studies may support the same broad claim while differing in the specifics. The ideal case we seek for a thorough confirmation is that exactly the same result (at some appropriate level of abstraction) was produced from completely different materials and methods. We can only know whether (or to what extent) this criterion is met when studies report their materials, methods, and results in concise, detailed, and comparable forms.
]]>Errors in scientific results due to software bugs are not limited to a few high-profile cases that lead to retractions and are widely reported. Here we estimate that in fact most scientific results are probably wrong if data have passed through a computer, and that these errors may remain largely undetected. The opportunities for both subtle and profound errors in software and data management are boundless, and yet bafflingly underappreciated.

Computational results are particularly prone to misplaced trust
Perhaps due to ingrained cultural beliefs about the infallibility of computation, people show a level of trust in computed outputs that is completely at odds with the reality that nearly zero provably error-free computer programs have ever been written.
It has been estimated that the industry average rate of programming errors is "about 15 - 50 errors per 1000 lines of delivered code" (McConnell, Code Complete). That estimate describes the work of professional software engineers--not of the graduate students who write most scientific data analysis programs, usually without the benefit of training in software engineering and testing. The most careful software engineering practices in industry may drive the error rate down to 1 per 1000 lines.
For these purposes, using a formula to compute a value in Excel counts as a "line of code", and a spreadsheet as a whole counts as a "program"--so many scientists who may not consider themselves coders may still suffer from bugs.
Table 1: Number of lines of code in typical classes of computer programs.
| Software type | Lines of code |
|---|---|
| Research code supporting a typical bioinformatics study, e.g. one graduate student-year. | O(1000) - O(10,000) |
| Core scientific software (e.g. Matlab and R, not including add-on libraries). | O(100,000) |
| Large scientific collaborations (e.g. LHC, Hubble, climate models) | O(1,000,000) |
| Major software infrastructure (e.g. the Linux kernel, MS Office, etc.) | O(10,000,000) |
| (via informationisbeautiful.net) |
How frequently are published results wrong due to software bugs?
Of course, not every error in a program may affect the outcome of a specific analysis. For a simple single-purpose program, it is entirely possible that every line executes on every run. In general, however, the code path taken for a given run of a program executes only a subset of the lines in it, because there may be command-line options that enable or disable certain features, blocks of code that execute conditionally depending on the input data, etc. Furthermore, even if an erroneous line executes, it may not in fact manifest the error (i.e., it may give the correct output for some inputs but not others). Finally: many errors may cause a program to simply crash or to report an obviously implausible result, but we are really only concerned with errors that propagate downstream and are reported.
In combination, then, we can estimate the number of errors that actually affect the result of a single run of a program, as follows:
# errors per program execution =
total lines of code
* proportion executed
* probability of error per line
* probability that the error meaningfully affects the result
* probability that an erroneous result is plausible.Scenario 1: A typical medium-scale bioinformatics analysis
All of these values may vary widely depending on the field and the source of the software. For a typical analysis in bioinformatics, I'll speculate at some plausible values:
- 100,000 total LOC (neglecting trusted components such as the Linux kernel).
- 20% executed
- 10 errors per 1000 lines
- 0.1 chance the error meaningfully changes the outcome
- 0.1 chance that the result is plausible
So, we expect that two errors changed the output of this program run, so the probability of a wrong output is effectively 1.0. All bets are off regarding scientific conclusions drawn from such an analysis.
Scenario 2: A small focused analysis, rigorously executed
Let's imagine a more optimistic scenario, in which we write a simple, short program, and we go to great lengths to test and debug it. In such a case, any output that is produced is in fact more likely to be plausible, because bugs producing implausible outputs are more likely to have been eliminated in testing.
- 1000 total LOC
- 100% executed
- 1 error per 1000 lines
- 0.1 chance that the error meaningfully changes the outcome
- 0.5 chance that the outcome is plausible
Here the probability of a wrong output is 0.05.
The factors going into the above estimates are rank speculation, and the conclusion varies widely depending on the guessed values. Measuring such values rigorously in different contexts would be valuable but also tremendously difficult. Regardless, it is sobering that some plausible values lead to total wrongness all the time, and that even conservative values lead to errors that occur just as often as false discoveries at the typical 0.05 p-value threshold.
Software is outrageously brittle
A response to these concerns that I have heard frequently--particularly from wet-lab biologists--is that errors may occur but have little impact on the outcome. This may be because only a few data points are affected, or because values are altered by a small amount (so the error is "in the noise"). The above estimates account for this by including terms for "meaningful changes to the result" and "the outcome is plausible". Nonetheless, in the context of physical experiments, it's easy to have an intuition that error propagation is somewhat bounded, i.e. if the concentration of some reagent is a bit off then the results will also be just a bit off, but not completely unrelated to the correct result.
But software is different. We cannot apply our physical intuitions, because software is profoundly brittle: "small" bugs commonly have unbounded error propagation. A sign error, a missing semicolon, an off-by-one error in matching up two columns of data, etc. will render the results complete noise. It's rare that a software bug would alter a small proportion of the data by a small amount. More likely, it systematically alters every data point, or occurs in some downstream aggregate step with effectively global consequences.
Software errors and statistical significance are orthogonal issues
A software error may produce a spurious result that appears significant, or may mask a significant result.
If the error occurs early in an analysis pipeline, then it may be considered a form of measurement error (i.e., if it systematically or randomly alters the values of individual measurements), and so may be taken into account by common statistical methods.
However: typically the computed portion of a study comes after data collection, so its contribution to wrongness may easily be independent of sample size, replication of earlier steps, and other techniques for improving significance. For instance, a software error may occur near the end of the pipeline, e.g. in the computation of a significance value or of other statistics, or in the preparation of summary tables and plots.
The diversity of the types and magnitudes of errors that may occur makes it difficult to make a blanket statement about the effects of such errors on apparent significance. However it seems clear that, a substantial proportion of the time (based on the above scenarios, anywhere from 5% to 100%), a result is simply wrong--rendering moot any claims about its significance.
What to do?
All hope is not lost; we must simply take the opportunity to use technology to bring about a new era of collaborative, reproducible science. Some ideas on how to go about this will appear in following posts. Briefly, the answer is to redouble our commitment to replicating results, and in particular to insist that a result can be trusted only when it has been observed on multiple occasions using completely different software packages and methods. This in turn requires a flexible and open system for describing and sharing computational workflows, such as WorldMake. Crucially, such a system must be widely used to be effective, and gaining adoption is more a sociological and economic problem than a technical one. The first step is for all scientists to recognize the urgent need.
]]>Why encrypt? It just raises your profile. If I've got something to say that really needs to be private, I think email is right out.
Good question, and one that takes some soul-searching.
First of all: to me it's a matter of principle. NSA: we want to read your email. DS: fuck off.
Second: encryption does actually work, even against the NSA, so long as the key length is sufficient (I use 4 kb RSA keys, which should be OK for a while). So I may "raise my profile"--indeed, encryption apparently guarantees that the NSA will store the email indefinitely--but only in a generic sense that I become a more "suspicious" person; my content remains secure.
Third, as a corollary of the first two: I'm flooding the system with noise as a form of protest, and thereby contributing to the cost of the NSA programs (a token drop in the bucket, I know). If it becomes cost-prohibitive to store all encrypted emails (and, later, to decrypt them), then they'll stop doing it, or at least they'll have to reduce the storage term, or the quantity decrypted.
Similarly, the more completely innocent people they flag as "suspicious", the less of the intended meaning that label will carry. Conversely, if a government wants to label me as suspicious when I'm clearly not, then my natural reaction is to be a dissident against that blatantly nutty government-- in which case I welcome the label. If I become so "suspicious" that the NSA escalates by hacking my laptop directly, or by digging deeper into my cloud accounts, or by harassing my employer, or whatever, then that can only waste their time while potentially exposing them as ever more criminal and giving me and the ACLU and the EFF ever more grounds to sue.
Fourth: good security practices remain effective against all other adversaries besides the NSA, e.g. wayward sysadmins; random hackers; malevolent employers; insurance companies; whatever.
Fifth: for legal purposes, encrypting something makes a strong assertion that the data is private, so--even if the encryption is easy to break--anyone with knowledge of the content of my email can't claim that they saw it inadvertently.
As for material that really does need to be private, like that plan we were talking about to hezbollah the intifadas with long-range nuclear embassy Yemen, I agree: absolutely no email, Skype, phone calls, or snail mail (all of which gets at least envelopes photographed and logged, if you didn't catch that one). Stuff like that must be communicated in person, naked, in a Faraday cage, or by some other channel that has been very thoroughly designed to provide an insane level of security-- which I haven't yet thought through because I don't actually need it.
The flip side of all this is that encrypting everything out of principle intentionally throws up chaff that could in the end just serve to make it harder for law enforcement to detect pedophiles and actual terrorists (in the real, non-diluted sense) and whatnot-- cf. yesterday's shutdown of a pile of Tor sites, at least some of which probably were really horrible. Such crimes can and should be investigated by standard procedures, including digital snooping with appropriate warrants.
But I'm sure you agree that mass collection of everything is a bridge too far, so I have no problem putting up some resistance against that even if I'm accused of thereby effectively harboring criminals. If the cost of freedom is a few more heinous crimes, so be it; we have to accept at least a little bit of unpleasantness if the only alternative is to cower in the face of a police state. Liberty/security/deserve neither/etc. etc.
As for designing protocols or algorithms to provide additional security beyond basic GPG encryption: that is seriously best left to experts. For instance:
Or maybe an encrypted message sent in two halves, as separate emails…
I think that provides no benefit at all. Anybody who has access to one half also has access to the other (they're certain to be sent over the same wires, stored on the same servers, etc.). Maybe it makes decryption infinitesimally harder because you have to match up the halves first, but that is trivial compared to the rest of the surveillance and decryption that would have to happen anyway.
In any case, the upshot is that I do encourage anyone with GPG set up to use it as much as possible; my key is 191C21C3. For those not hooked up yet, I'll write up a quick howto soon-- it's really easy.
]]>My Master Signature Key is used only for signing keys and collecting signatures. If you wish to sign my key, please use this one. Please verify the fingerprint with me in person before signing it, of course.
pub 4096R/D8D9E1FD 2008-11-09
uid David Alexander Wolfgang Soergel (Master Signing Key - http://www.davidsoergel.com/gpg.html) david@davidsoergel.com
This is my Daily Use Key, to which emails should be encrypted, and with which emails from me will be signed:
pub 4096R/191C21C3 2013-06-27 [expires: 2018-06-26]
uid David Soergel (http://www.davidsoergel.com/gpg.html) lorax@lorax.org
Because my Daily Use Key is signed with my Master Signature Key, it is not necessary or useful for anyone else to sign it directly. Just import both of the keys, update your trustdb, and all should be well.
In the past, I kept a Backup Key, in addition to the Daily Use Key, but with the same properties. It was used for encrypting backups that I store in the cloud. I no longer see the point of doing that; I'll just encrypt backup with my Daily Use Key. That key identifies me, and only I may decrypt my backups.
These old keys have expired:
See also: Thoughts on GPG key management.
]]>Mutable names represent substitutable artifacts
Digital artifacts, such as jar files, are unique things; in a world of final variables, each must have a different name. The most concrete way to express dependencies among artifacts, then, is to refer very precisely to the exact build (for instance, using the hash of the jar file as an ID). However this does not allow for a lot of flexibility that we'd like to have when composing sets of dependencies, and in dealing with transitive dependency conflicts.
Version numbers are a means of variable mutability: we want to be able to refer to different actual artifacts by the same name. The point of doing this is that we expect them to behave similarly, i.e. to be substitutable.
In the Maven/Java context, aside from the "group ID" and "artifact ID", the package and class names contained in the jars constitute mutable names too, because they are the key used for classpath searching. To really enforce an immutable worldview, we'd have to add a build number to the class names themselves (!), or perhaps in a package name (e.g., com.davidsoergel.dsutils.8474.StringUtils). A similar effect can be accomplished with Maven Shade. But of course that is not what we want.
The question of whether artifacts are substitutable or not is really a continuum: minor version number updates are likely substitutable, but major ones are often not. Sometimes package authors (or user communities) make non-substitutability of major versions extra explicit by making the version number part of the name (e.g., Maven2), indicating that the new product serves a similar purpose to the old one but has a completely different API. Similarly, sometimes artifacts keep their name but move from one group to another (often for apparently beaurocratic reasons); this makes the artifacts appear completely distinct, breaking the possibility of version substitution.
Any anyway, the degree to which one artifact can be substituted for another depends on the task. A common pattern is backwards compatibility: core functionality continues to work but later versions add new features. In that case, a dependency should point to the oldest version that will work, since pointing at a newer version suggests that the newer features are used when in fact they're not.
Conversely, there may be different implementations of the same API, which are in fact substitutable despite having different names. This is sometimes handled (poorly, e.g. in the case of Java XML parsers and logging packages) by making the API an artifact in its own right, containing singletons or factories as needed so that implementations can be swapped at runtime simply by placing one or another on the classpath.
Dependencies by duck typing
A lot of confusions around dependency version numbers might be alleviated by expressing a dependency simply by a set of tests. This is something like duck typing or "structural typing" in Scala: if a library works for our purposes then we can use it. This is somewhat related to "behavior driven development"), with the twist that the downstream users write (or at least select) the tests that they care about to satisfy the dependency. In the simplest case, of course, the user can just specify "all the tests", but this may be a more stringent requirement than is really needed. Automated tools might assist is selecting a relevant set of tests, for instance using code coverage metrics to find tests that exercise the same library code that the user's program does.
A related issue is the granularity of artifacts: finer grain requires more management overhead, but allows paying attention to only those changes you are likely to care about. Some projects model this by providing a number of of related artifacts a la carte. In general it's accepted that, when depending on a library, you drag along a lot of stuff you don't need. But when that stuff changes, the version number increments, and it's hard to tell if that's relevant to your program or not. In the limit we could give every class, object, method, etc. a version number! But packaging coherent sets at some level is essential for sanity. When the packaged objects form a tightly connected cluster, that makes sense anyway; when they don't (e.g., dsutils), then nearly every version update is irrelevant to nearly every dependent program, but that's the cost of not packaging each class individually.
Of course, substitutability may not just be a matter of tests passing; maybe there are performance differences, or untested side effects, or important functionality which lacks a test.
Versioning tests
Tests should be versioned separately from the main code, although naturally the tests will depend on certain versions of the underlying code (or, in a behavior-driven model, will just fail). Consider the case of package Foobar versions 1.0, 1.1, and 2.0. Initially a bunch of tests of core functionality pass for all three, so a user believes that they are substitutable. But then it turns out that a required function was just untested, so the user adds a test for it (and perhaps but not necessarily submits it back to the package maintainer). The new test reveals that things started working in 1.1. However, that test should not be attached to the 2.0 code base. It could go on a numbered 1.1 branch (e.g., 1.1.01), I suppose, but it seems wrong to increment the main version number since only the tests changed and not the actual code. Or, it should it go on a 1.0 branch, showing that the original release actually didn't behave as expected.
So a test should always be runnable against the earliest version of the code where it was expected to pass. Such tests can then be run against later versions of the code to demonstrate backwards-compatibility.
But what if an API change, or even an underlying functionality change, make the test fail in a later version--but that is considered the correct behavior? Then the library is no longer backwards-compatible with respect to that test. That's OK, as long as we're measuring compatibility based on sets of passing tests. In this view, the failure of some test does not mean that the library has a bug; it means only that the library is not compatible with a given expectation, about which some downstream users may not care. Others who do care about that functionality will know which versions to use or not. Indeed some users may prefer the opposite expectation, represented by a different test. (Of course, a set of tests encoding a coherent set of expectations should nonetheless reveal bugs!)
So, why not go ahead and run all tests against all versions of the code? Sure, tests written for v2.0 will usually fail against v1.0 (likely with ClassNotFoundException and such), but that will provide the raw data for what works and what doesn't in every version. Most importantly this allows completely decoupling test versions from code versions, which in turn enables the behavior-based specification of dependencies above.
Conflict resolution
In the status-quo systems, e.g. Maven2 and Ivy, conflicting dependency versions are resolved by pluggable strategies, including things like "latest revision" and "latest compatible".
Apparently the usual syntax for specifying a dependency version in pom.xml file indicates only a preference, not a requirement. However, both Ivy and Maven allow specifying a specific version, or a range of versions (bounded or unbounded, inclusive or exclusive). As far as I can tell they do not allow specifying discontinous ranges, though in reality that is a common case (e.g., 1.0 worked, 1.1 introduced a bug, 1.2 fixed the bug).
Those dependency constraints are placed at the point in the tree where the dependency is specified (i.e., at the intermediate node that actually needs it). In addition, "
In a behavior-typed dependency system, all that is needed to resolve multiple transitive dependencies is to find an artifact meeting all of the specified requirements. This automatically allows for the case of accepting discontinuous ranges, and allows various nice heuristics for selecting among them. For instance, one might argue that the version of a library in which the desired functionality is most stable would be the last in the longest series of compatible versions, or (by a similar argument) the latest minor version of the oldest major version. It also allows choosing a runtime-swappable implementation of an API: it shouldn't matter that two artifacts have different names, as long as they pass the same tests.
Improving conflict resolution with data
To the extent that dependency version constraints are specified in a pom or similar: that should be stored in a separate source repository. As upstream dependencies are updated, it may turn out that certain versions work with a given project and others don't; there's no way of predicting that when packaging the dependent library. We'd like to be able to update the dependency constraints--a sort of metadata--without touching the underlying data.
In fact, perhaps dependency versions should not be in poms at all, since compatibility is more an empirical issue than a proscriptive one. But where can we get the empirical data? From all of the millions of daily compilation and testing jobs run worldwide! All of that data can be collected automatically (with user permission, of course). In the case of the Java ecosystem, for instance, Maven/Ivy/SBT plugins would do the trick.
Crowdsourced info on which pairs/triples/bundles of versions of things are mutually compatible. This data helps to cover the gap of code for which no explicit tests have been written. If downstream tests happen to exercise upstream code, and they give the expected results, that's some indication that the upstream code was OK; and conversely downstream test failures at least cast some doubt on untested upstream code. In other words: sufficent integration tests can provide some sense of security when unit tests are lacking. For better or for worse, this is effectively what happens in real life anyway: lots of code goes untested, but developers shrug because it appears to work in the aggregate.
Crowdsourced info on which versions of things are effectively equivalent. Possibly, try to distinguish version updates that are just bugfixes from version updates that introduce new features. This falls out of #1: every time two different versions of something both work with a given downstream component, that increases their equivalence score.
Crowdsourced info on which specific tests pass in which "worlds" (i.e., sets of component version numbers). I.e., back off the "perfect equivalence" definition to allow finding equivalances with respect to only certain functionality.
The design of a distributed system for collecting, managing, and distributing these data remains an exercise for the future.
Testing all artifacts in a consistent world
The idea that we fetch dependencies transitively in response to their declaration in a pom seems backwards. Instead we should propose a world by providing exactly one version of each library, and then recompile and test everything to determine whether the world works. This guarantees that a library is run using the same version of its dependencies against which it was compiled. In the status quo, a library may well be compiled and tested against one set of versions, but then its binaries are distributed and run against another set of dependency versions. This seems obviously error-prone.
A automated build process should proceed in phases:
- collect the list of dependencies transitively declared, with all of their constraints (whether expressed as version numbers or as test sets).
- For each of the dependency names, collect the list of versions available in the wild together with their test results.
- Choose the most recent set of versions that satisfies all of the constraints (or throw an error if not possible), according to some selection strategy. (This is Ivy's "latest-compatible" setting).
- Collect the chosen artifact versions into a private "world", ideally in source form, and including their associated tests.
- Compile all the artifacts in partial order. This demonstrates that the APIs in this world are all compatible.
- Run all the tests. Here, these are intended as integration tests: they show that particular version bundles are mutually compatible. Iff the tests for a given package and for all of its transitive dependencies pass, report success for that bundle. (If the tests are really comprehensive, then the compilation step is not needed, since any mismatched APIs will result in a runtime exception in the tests. However, compilation will catch API mismatches that are not exercised by the available tests.)
Version control changeset ids, build numbers, and version numbers
Given a deterministic build process, a given version number associated with a binary distribution (e.g., v2.2) is just a friendly name for a specific version of the source code (e.g., 7eae88hc) that happens to have been built. Usually the source code should be "tagged" with the friendly name. The build number is another tag for the same version, but ought to be irrelevant since the build should be exactly reproducible from the sources. So in general when I speak of "version numbers" throughout I really mean source code revisions. This is important because of the need to recompile things to confirm API compatibility.
The other thing that friendly version numbers can be good for is bundling a release of multiple source repositories that form a coherent whole (see the granularity issue above): that is, it's a means of declaring that a given set of artifact versions ought to work together.
Conclusion
Dependency resolution is a hairy mess, largely because existing solutions depend on version numbers. These provide essentially no information about the provided functionality or compatibility with other components; thus, knowing that a specific version of some component works in a given context allows no inferences about whether other versions would also work. This fact hampers automatic updating of components over time and automatic resolution of dependency conflicts. These issues may however be resolved by basing dependencies on acceptance criteria in the form of reproducible tests, rather than on their version number proxies.
See also
I.-C. Yoon, A. Sussman, A. Memon, and A. Porter. Direct-dependency-based software compatibility testing. In Proceedings of the 22th IEEE/ACM International Conference On Automated Software Engineering, Nov. 2007.
I.-C. Yoon, A. Sussman, A. Memon, and A. Porter. Effective and scalable software compatibility testing. In Proceedings of the International Symposium on Software Testing and Analysis, pages 63–74, Jul. 2008.
I.-C. Yoon, A. Sussman, A. Memon, and A. Porter. Prioritizing component compatibility tests via user preferences. In Proceedings of the 25th IEEE International Conference on Software Maintenance, Sep. 2009.
I.-C. Yoon, A. Sussman, A. Memon, and A. Porter. Towards Incremental Component Compatibility Testing. In CBSE '11: Proceedings of the 14th International ACM SIGSOFT Symposium on Component Based Software Engineering, 2011.
]]>The problem: it's hard to keep track of web browsing
One of my various mental diseases is that I keep far too many tabs open in my web browsers. Similarly I have vast numbers of bookmarks, mostly stored on Pinboard but also in Read it Later. In fact I rarely refer back to these, but that's more because they're so poorly organized and unwieldy to deal with; if I know more or less what I'm looking for, it's faster to just do a fresh Google search. Why then store bookmarks at all, or even keep open tabs?
For me there are a couple of possible reasons:
I'm afraid to forget about a given topic entirely. This is certainly the case for news stories: if I mark an article as interesting based on the headline, I certainly wouldn't remember and search for it later; the only way I might actually read it is if it goes on a "to read" list of some kind. But it also applies to tasks or mini-projects that manifest themselves as web browsing sessions, where an open tab might remind me: "oh yeah, I was browsing Amazon reviews of motion-sensitive LED lighting for closets, but I got distracted." So my open tabs sometimes function as a sort of to-do list regarding projects in progress, which (if I'm not tracking them somewhere else) I might otherwise inadvertently drop.
If the cost of finding something was high (i.e., not the first Google hit on the most obvious query), then I want to save the cost of recapitulating the search. If the answer to my question was very hard to find the first time, I might even fear that I just wouldn't find it at all if I had to try again from scratch.
Benefit of familiarity: even if a later search on a similar topic would turn up an equally informative page, I'd prefer to return to a page that I've already seen-- it will be easier for me to navigate if it's familiar.
Tree-like browsing. I often want to explore multiple links from a given page; if I just click on the first one, then obviously I'll soon lose track of the other links that I intended to visit, and even the page that they were on. The simple "forward" and "back" navigation does not model the naturally branching structure of browsing. (I think I've seen some experimental browsers or plugins that tried to track this, but they were unwieldy; the SnapBack feature in Safari is an example that is now defunct because it was too confusing). For now I deal with this by opening a tab for every link I want to follow from a given page. Together with Tree Style Tab, this works pretty well but leads to many open tabs.
There are a number of mechanisms that people use to keep track of interesting URLs: browser history (perhaps in multiple browsers, or on different machines), open tabs, saved tab sets/browser sessions, local bookmarks, social bookmarks, Read it Later/Instapaper, starred items in Google Reader, RSS feeds, and so forth. Synchronization schemes do exist within and among some of these, but in general they are poorly interoperable. So the minute you use more than one of these mechanisms things become Confusing, and in practice it's hard to avoid using at least three or four.
But all of these are special cases of a single idea: keeping track of a URL, possibly together with a bit of metadata, such as tags and date visited. Even an open tab is just a bookmark; the only difference is that it's easy to return to with a single click, and it "loads" quickly. An item from an RSS feed is just a "bookmark" that has been never visited (and that has not even been accepted as interesting).
So, here I propose a new user interface for web browsing that unifies the disparate means of tracking, flagging, and tagging visited URLs. The goal is to just directly support the way humans actually use the web.
One window to rule them all
Humans do not multitask; our attention falls on exactly one thing at a time (though we may switch rapidly among them). Thus the very idea of parallel, simultaneous tracks of attention is harmful to how we actually work. But this is exactly what tabs are: they represent the idea that a number of different web pages can somehow be simultaneously within our attentional scope. Since that is not the case, we should do away with browser tabs. There shall be only one browser window, showing the page that currently has our attention. That's it.

Bookmarks and tabs are just flagged history items
As is already familiar, the browser keeps a history of each URL shown, together with the times when it was loaded. The functions previously served by tabs are better provided by the idea of flagging items in the browser history as "active". Obviously a URL cannot be loaded in a tab if it is not also in the history, so in my current usage the fact that a tab is open is equivalent to "blessing" a history item with a flag meaning that it "deserves further consideration".
Similarly, a bookmark is just an item that was previously visited--hence in the history--which has been flagged as "worth keeping track of". It may additionally have tags associated with it, whether entered by hand or suggested by a social-bookmarking service.
A user's history is a single stream
When a user visits a page, that fact is immediately stored on a cloud service. The history is meant to represent the history of pages viewed by the user, regardless of in which browser or on which device. Metadata is synchronized too, of course, including the "active" and "bookmark" flags above.
The history is always visible, but can be filtered and sorted
A list of history items is shown in a sidebar. It may be filtered to show only "active" items, or only bookmarks with a given tag or set of tags. It may be sorted by date, by priority, or by some sense of relevance (see below).
Active history items are a todo list
To the extent that items flagged "active" in the history (the former tabs) are marked thus because they require attention, the set of these comprises a todo list. The task for each URL is to read the page and perhaps do something about it. Thus the history records may have appropriate metadata, such as deadlines (perhaps repeating, as in OmniFocus), priorities, and contexts (in the GTD sense).
Put differently: each history item may be given an urgency ranking, which is the same as a revisit start or stop date:
- revisit never (abandon)
- revisit sometime (interesting but not urgent)
- revisit next week (interesting and somewhat time sensitive)
- revisit now (remain active)
History items are automatically tagged
Manual tagging of pages is too much work to be plausible for most people. So, items can be automatically tagged, by a number of possible mechanisms:
- Automatic acceptance of social-tagging suggestions.
- Context clues: which browser, which machine, time of day, location (when available).
- Markov tagging: especially when I follow a link from a given page (which has some tags), it's likely that the next page should have the same tags. Similarly, when I look at two URLs close in time, they are likely to relate to the same tags. (That is: the Markov chains in question should operate both in the link-chain sense and in the chronological sense).
- Sticky tags: the user may type some tags (e.g., the name of a project that the current browsing session is about) that are automatically applied to every page.
Tags inferred by these various mechanisms are shown at the top of the browser window for every page, as soon as it is loaded. The user thus has an opportunity to edit them (with no extra clicks or navigation to a "tag edit" screen), but also can simply view and accept them by doing nothing.
History results may be context-sensitive
One way to sort or filter the displayed history items is to consider the context of what the user is currently doing. This may be represented by the currently active sticky tags, as well as the same context clues above (device, browser, time, location). One might also consider clues from the currently viewed page (or the history of the 10 most recently viewed pages), such as tags, social tagging suggestions, the domain of the URL, word frequencies in the text, and inbound and outbound link structure (given Google-like data). The point of all this is to provide "related items" as one of the selectable views of the history.
Topic modelling
The natural extension of the above is to run an off-the-shelf topic modelling tool such as Mallet on the full text of all history items. "Related items" might then include those pages with similar topic vectors. A newly visited URL can be classified into an existing topic model, and this can be used to suggest tags (not only those that others have used, but also those that this user has used for similar pages).
Better yet, a Factorie-based approach (presumably involving a fairly compute-intensive cloud service) could continuously refine the topics and tags, as the user visits and tags new pages. This mechanism would propagate suggested tags both among users and within a user (i.e., pages containing similar topics should have similar tags), and could take inferred tags and other metadata into account (though with a lower weight than manually-assigned tags).
Obviously topic-modelling the entire web would be a substantial undertaking; here the hope is that the document sets to be processed are much smaller--perhaps a few thousand per user, or tens of millions for a joint model among users, but not (yet) tens of billions.
It's worth noting here that DevonThink does quite a good job of sorting documents into preexisting categories (provided that these contain enough examples already). It is not so good at generating the topics de novo, though.
Semantic relationships among tags
"Folksonomies" deal poorly or not at all with synonyms, alternate spellings, and semantic relationships among tags (such as is-a and containment relations) that are the stuff of full-fledged ontologies. Here, we may learn relationships among tags, both per user and jointly, simply by their co-occurrence in tag lists (0th order) or by co-occurrence in sets of related documents (in a sense, topic modelling over the tag sets of document clusters). Thus a search for "cooking" may return results tagged "recipe", through a mechanism that is entirely emergent from user data.
It may also be useful to allow users to specify some simple relationships, such as synonomy or containment; that way a user may tag something only "Scala" but then retrieve it in a search for "programming".
Diversity slider
A slider allows the user to select the "diversity" of the shown history items, from "same" to "different". When "same" is selected, the results are what you would expect given the other filtering and sorting choices: the most recent pages, the most related pages, the best matches to a query, etc. But as the slider is moved towards "different", and ever-broader selection of divergent pages (e.g. older, or poorer matches, etc.) is shown. Past a certain point, these are grouped and briefly summarized: e.g. by date or by topic. When documents are tagged or topic-modelled, the scope of the topics and possible containment relationships can be used to present an ever more diverse view. For instance, when viewing a recipe for chocolate cake, selecting "same" might produce alternate recipes for chocolate cake, and sliding towards "different" might give recipes for other chocolate desserts, then for desserts generally, and so forth.
Admittedly this feature needs a good deal more thought; the point is just to allow the user to "zoom out"--and then back in again--along whatever dimension is indicated by the other sorting & filtering choices: time, topical relatedness, etc.
Bulk retagging UI
A substantial frustration with existing tagged-bookmark systems is that it can be surprisingly hard to manage tags in bulk: for instance, to select a large set of bookmarks and add a tag to all of them, or to remove a tag from a set, or to rename a tag. Fixing this requires two things: 1) a simple UI (for which the iTunes bulk metadata editor is a reasonable model) and 2) an underlying data representation that allows making such changes efficiently. One possible reason why the current state of affairs is so lame is that tags often seem to be stored in a fully denormalized manner, as text strings attached to each URL.
Conclusion
A web browser taking this described approach is a form of intelligent assistant, explicitly helping the user to focus his or her attention on high-value information, while at the same time lending confidence that history is automatically captured and categorized. Such a browser is but one example of an "attention management" tool, of which others may apply similar principles to various tasks other than web browsing.
As with all of these half-baked ideas, please let me know if you'd like to help build it!
]]>Update (May 2013) Since this was written, we implemented a lot of it at OpenReview.net, and wrote a fairly comprehensive paper about it.
The initial review period
- REs competing to rate the best papers first: does this create a first post race, favoring shallow over deep reviews? Maybe all reviews should be embargoed to some date (i.e., 1-2 weeks after publication) and released simultaneously. In fact, what's the rush to be first to review? Is that worth more points (or, there is a multiplier on the karma associated with the review, to reward promptness)?
- When an author requests a review from a specific RE, reviews from other RE's should be embargoed-- that is, the designated RE gets a lock on the paper for 2 weeks, so that they can give it full attention without getting scooped.
- Could allow a double-blind option for extra karma. That is: I might get 1.2x karma for reviewing something without knowing the authors. Upon submission, give authors the option for a 2-week blind period. Careful that someone's "anonymous" karma increments vs. time don't reveal what what they reviewed (maybe keep a "private' karma pool which trickles into the public score randomly over time, to obscure the source).
- Bad papers pose no reviewing burden: circular. How do you know they're bad?
- On reviews being first-class papers: yes, but reviews likely lack formal structure and may be less well written; tweets are on the end of that continuum. For that matter a simple upvote is a one-bit "review". Conversely a really detailed rebuttal of something may take the form of a full paper. How does credit scale with length & effort?
Paper revisions
- When a paper is updated, what happens to its reviews? They're still connected to the old version. Is it expected that the reviewers will review the update as well, to indicate whether their concerns were adequately addressed? How many rounds are expected?
- When is a paper "done"? Maybe there should be some time limit, say 12 months, after which that paper is fixed and any updates must take the form of a new paper (or a retraction)
- Authors could tag work on the brainstorms->done scale. B. Schoelkopf points out that journals publish complete work, but conferences may accept work in progress.
- How much credit arises from a good revision vs. a good original paper? Will there be a perverse incentive to submit a "new" paper that is really an untracked revision of the old one?
- What if a paper gets a great review, but then a later version introduces a fatal bug? Does the great review still grant credit? Or, is the reviewer responsible to add a negative review of the later update?
- To address the concern that a bad review may stick with a naive young grad student for a long time: if the reviewer accepts a later revision, allow the original bad review to be hidden. (I.e. the record that it happened should remain, so that the reviewer gets credit). Maybe it costs the author a few karma points to hide the review, and it should require the consent of the reviewer, and maybe copying any outstanding issues into the updated review.
Karma assignment
- Should really bad papers get negative points, instead of just being ignored? Yes. Disincent flooding with crap.
- If reviewing a paper that later becomes successful benefits the reviewer, then there might be "gold rush" to submit not-very-helpful reviews on lots of papers that are already getting good reviews or that come from infuential labs. So the credit to the reviewer accruing via a successful paper must be multiplied by the quality of the review itself. Maybe nonlinearly: e.g. a review gains no credit until it has at least five upvotes, etc.
- The karma system may reflect not just quality but also politics: people may trash others they don't like, etc. Converse of rich get richer: people may get shut out on purpose. The hope is that personal squabbles will be noise, drowned out by unbiased reviews. If the whole community really shuts out a person or topic, well, that's the way it is (as the climate change deniers complain), and our modeling it is legit.
- Computing karma flow on the citation graph requires sentiment analysis. E.g. "in contrast to the boneheaded claims of Fritz et al. 2004, ..." might produce negative karma for Fritz.
- On the other hand, if we're measuring paper visibility, not paper quality, then a negative-sentiment citation is still a "good' thing: the paper must have been visible enough to get cited in the first place, and now it's even more so.
- Need to support multiple scoring schemes, which amounts to the same thing as multidimensional scores. A person may accrue karma form lots of average papers or from a few good ones, or primarily from reviews (not papers, if there is any distinction anyway), etc. (Similar reason for different bibliometric scoring schemes e.g. H-index etc.)
- Fractional authorship allows "acknowledged" people to get a bit of credit (e.g., 1%). The other part of authorship is vouching for the contents; either make this distinction explicitly, or just have a rule that authors > 5% are not responsible. Also, acknowledgement does not require consent, but authorship does.
Conference mechanics
- Highly rated people should be invited to the conference and/or given travel awards. Sets up competition to get to go.
- System could allocate conference presentation time according to author request (i.e. based on the length & difficulty of the paper), reviewer request, and karma. E.g. one paper gets a 17-minute slot, another 6 minutes, etc.
Cultural issues
- Could get awkward if a grad student has a higher score than a PI.
- The big impact of the short-term conference site might be to make us a focus of discussion about how academic publishing can be fixed; i.e. our "meta" site becomes the place where this topic gets discussed.
Other notes
- In my undergrad thesis (14 years ago!), I covered the basic idea of the Reviewing Entity as essentially a node in a distributed trust network-- and surely the concept was not new then either. The idea that we rely on external authorities to give us information, but that we trust them to varying degrees and for different purposes, is self-evident. It's just a matter of finding and implementing the right abstraction for that fact.
A "treemap" provides a natural visualization for this kind of data, because it can simultaneously represent hierarchical structure (through the 2d layout) and two continuous variables (tile size and color), and guarantees that everything fits on one screen. So, I wanted to visualize my current todo list, grouped by context, with the tile size corresponding to task duration and the color corresponding to the due date (i.e., to see how far overdue something is). Alternatively, one might want to color things based on whether they're flagged or not, or make tile size correspond to urgency in some way instead of duration, etc.
There are various treemap visualization programs available, but as far as I can tell only Treemap 4.1 (by the original inventor of treemaps) is freely available and reads arbitrary data (as opposed to the various disk-space-mapping tools such as DiskInventoryX). To try it out, I wrote a very simple perl script (of2tm3.pl) that translates OmniFocus CSV exports into the tm3 format that Treemap 4.1 can read. Here's an example showing things on my plate today:

In the Treemap program, hovering on a tile shows a tooltip with more detail about that task.
Note that the OmniFocus export function dumps whatever is in the current view, so you can structure the map by project or by context, and filter for due items, flagged items, etc.
Obviously the graphical presentation could be much improved. This visualizer is from 2000-2004, and various more recent treemap programs look a lot better. The translation script does not at the moment map the numerical hierarchy IDs to project/context names, which is why the groupings in the visualization are numbered and not named. But as a proof of concept I was pretty pleased that this was so easy to do.
Providing a view like this within OmniFocus (with live updating, of course) would be awesome in my opinion.
]]>TestNG does not explicitly support Contract Tests, as far as I can tell, but it’s fairly easy to make it work using the little trick I describe below.
For an interface or abstract class called FooBar, make a test class called FooBarInterfaceTest or FooBarAbstractTest or whatever.For an implementation FooBarImpl, we could make a test FooBarImplTest that just inherits from FooBarInterfaceTest. But what if FooBarImpl implements multiple interfaces, or extends an abstract class in addition to implementing one or more interfaces?
I thought about making one inner class (inside FooBarImplTest) per interface, each inheriting from the appropriate InterfaceTest. But, that doesn’t work because TestNG doesn’t recognize tests inside inner classes (or even static inner classes).
My solution is to use the TestNG @Factory annotation, which marks a method that returns a bunch of test cases in an object array. We can put such a @Factory in the implementation test class, and use it to return Contract Tests for each of the implemented interfaces or extended abstract classes.
Since the abstract tests will need to create instances of the concrete implementation being tested, we’ll need to provide the abstract test case with a factory for the test instances. I use a simple generic interface to describe the factory:
public interface TestInstanceFactory<T>
{
T createInstance() throws Exception;
}Then the Contract Test looks like this:
public abstract class FooBarInterfaceTest
{
private TestInstanceFactory<? extends FooBar> tif;
public FooBarInterfaceTest(TestInstanceFactory<? extends FooBar> tif)
{
this.tif = tif;
}
@Test
public void someFooBarMethodTest
{
FooBar testInstance = tif.createInstance();
...
}
}That creates the problem that the only constructor for the FooBarInterfaceTest requires a TestInstanceFactory argument. If FooBarInterfaceTest were a regular class, then TestNG (or at least the IntelliJ IDEA plugin) would try to instantiate it as a regular test, failing because there’s no zero-arg constructor. The trick there is to make the Contract Test class actually abstract, as indicated above, and to concretize it inline in the @Factory method in the implementation test (see below).
I put some logic for collecting all the Contract Tests relevant to a given implementation test into an abstract class (from which the implementation test will inherit):
public abstract class ContractTestAware<T>
{
public abstract void addContractTestsToQueue(Queue<Object> theContractTests);
@Factory
public Object[] instantiateAllContractTests()
{
Set<Object> result = new HashSet<Object>();
Queue<Object> queue = new LinkedList<Object>();
addContractTestsToQueue(queue);
// recursively find all applicable contract tests up the tree
while (!queue.isEmpty())
{
Object contractTest = queue.remove();
result.add(contractTest);
if (contractTest instanceof ContractTestAware)
{
((ContractTestAware) contractTest).addContractTestsToQueue(queue);
}
}
return result.toArray();
}
}And finally we make the implementation test, thus:
public class FooBarImplTest extends ContractTestAware<FooBarImpl>
implements TestInstanceFactory<FooBarImpl>
{
public FooBarImpl createInstance() throws Exception
{
return new FooBarImpl();
}
public void addContractTestsToQueue(Queue<Object> theContractTests)
{
theContractTests.add(new FooBarInterfaceTest(this){}); // this is the trick
}
}Two problems remain:
- although
FooBarImplTestextendsContractTestAware, TestNG doesn't find the inherited@Factorymethod. So we have to override it inFooBarImplTest:@Factory public Object[] instantiateAllContractTests() { return super.instantiateAllContractTests(); }
- As written above, the
FooBarImplTest@Factorymethod still isn't found because there is no@Testmethod present. So, in the unfortunate case that you don't have any real tests for the implementation class, you can just do this:@Test public void bogusTest() { }
that will cause the `@Factory` method to be found so all the Contract Tests will be run.That’s it! Note you can add as many Contract Tests as you want for each implementation test.
Also, although I’ve emphasized using this approach to test interfaces and abstract classes, there’s no reason you couldn’t use it for regular classes as well. You could do this if you’re in a situation where a subclass ought to pass all of the tests for its superclass (perhaps in addition to tests specific to the subclass).
Note too that this solution is chainable, so the test interface/class hierarchy can mirror the real interface/class hierarchy. For instance, if the FooBar interface extends another interface, say Baz, then FooBarInterfaceTest can itself extend ContractTestAware in order to provide a BazInterfaceTest (initialized with the provided concrete factory).
public abstract class FooBarInterfaceTest extends ContractTestAware<FooBar>
{
private TestInstanceFactory<? extends FooBar> tif;
public FooBarInterfaceTest(TestInstanceFactory<? extends FooBar> tif)
{
this.tif = tif;
}
public void addContractTestsToQueue(Queue<Object> theContractTests)
{
theContractTests.add(new BazInterfaceTest(tif){});
}
}Obviously, any change to a Contract Test will be automatically applied wherever it's appropriate. That is, by following this methodology, all concrete classes implementing the interface will be always be tested with the current version of the Contract Test.
]]>- Edit the old key to have an expiration date, and send the new version to the keyservers. Once it has expired, revoke it for good measure.
- Create a new Master Signature Key on a Knoppix system with no internet connectivity, and store it directly onto my secure flash drive ("the vault"), together with its revocation certificate. The vault will never be mounted on any machine that is connected to the internet. Using a second (less secure) flash drive, copy the public key to my laptop and, from there, send it to the keyservers.
- Create a second new key for daily use, with an easier passphrase.
- Sign the "daily use" key with the "master" key (again using a clean Knoppix system, since that's the only place the Master secret key should ever be available).
- Store the "daily use" key along with its revocation certificate in the vault, but also import it (both public and secret keys) to my regular laptop keychain.
- Perhaps, create additional keys for different purposes, storing them and their revocation certificates in the vault and signing them with the master key as appropriate.
Separation of Master and Daily Use keys
There are several reasons to separate the master key from the communication keys (inspired by Mark Haber's page on the topic). Note that I mean completely distinct keypairs, not the subkeys already built in to the GPG system.
- First of all, the benefits associated with subkeys apply, namely that the master key never expires but the daily use keys do.
- Second, I want to protect my master private key very carefully, e.g. by not carrying it around on my laptop, or allowing it to be copied to backup tapes that I may lose track of. If the master key were the key I used for communication, then I wouldn't be able to sign or decrypt anything on my laptop, which is clearly impractical.
- Finally, I want the master key to have a very strong passphrase, but I don't want to have to type that in all the time-- both because it's a hassle, and because typing the passphrase at all is a security risk (due to possible keyloggers, hidden observers, etc.).
So, this scheme allows me to use a weaker passphrase on the "daily use" key, without sacrificing passphrase strength on the master key. Also, I can expire the "daily use" key regularly (or revoke it at any time and make a new one), without losing the signatures on my master key.
The upshot of this is that someone who wants to communicate with me without performing any key verification (a bad idea) would need only my "daily use" public key; but someone who wants to verify that key would need the "master" public key in addition, since that is the only source of a signature on the "daily use" key. A disadvantage of this scheme is that the length of the key path to the "daily use" key is one hop greater than it would otherwise be, meaning that the web-of-trust algorithm is less likely to assign validity to it.
Why I don't use subkeys
What advantages does a subkey have over a second primary key signed by the first? Sure, there are advantages to having a "daily use" key that expires and differs from the long-term master signing key. But the technical act of making the "daily use" key a subkey of the "master" key (or, similarly, making an encryption key a subkey of a signing key) serves no purpose as far as I can tell.
Disadvantages of subkeys:
- I find them Confusing.
- There are disturbingly many (i.e., any at all) bug reports on the web about gpg software handling subkeys incorrectly.
- It is possible to export a subkey and attach it to a different primary key, creating a potential security hole.
- No ability (without a lot of hassle, anyway) to use different passphrases on primary and subkeys.
So, why bother with them at all? We can get all the advantages of subkeys (essentially, reduced trust of commonly used keys, with expiration) by just signing one primary keypair with another. Advantages of using only primary keys:
- easier to understand, less chance of human failure in applying encryption correctly.
- easier to manage, e.g. I can copy my email key to my laptop but leave my master signing key secure in my safe.
- separate passphrases.
The only disadvantage I can think of is that this scheme induces an additional hop in the web-of-trust model, and so makes the daily-use keys less likely to be trusted. I don't care, honestly. All of the people I want to communicate with will sign my master key directly, and if there is a web-of-trust thing going on I don't mind enforcing an extra level of paranoia.
Protecting the Master Signature Key
The Master Signature Key (together with its revocation certificate!) will live only on the "vault" flash drive and on two CDs stored in two secure locations, together with printouts to guard against technical failures in reading the CDs in the future. It will not be stored on any hard drive anywhere. If for any reason I want to discard a CD or printout containing the Master Signature Key, these should be convincingly destroyed, e.g. by shredding, burning, etc. The "vault" flash drive and the CDs should never be mounted on a machine with internet connectivity; thus, key-management operations are best performed in a Knoppix environment.
I also store other confidential information on CDs, but the CDs containing the Master Signature Key and its revocation certificate should contain nothing else. The reason for this is that I may need to update other information more frequently, resulting in burning a new CD and discarding the old one. By keeping the Master Signature Key on a dedicated CD, I reduce the number of times that old versions of the CD need to be destroyed. (Old versions of the other CDs may require destruction anyway, but that's a separate issue).
Under this scheme I won't need to use the Master Signature Key very often; in fact, since nothing should be encrypted to it, the only thing it will be ever used for is signing other keys. This is infrequent enough that retrieving the CD and booting up Knoppix when the need arises is not too inconvenient.
Protecting the Master Signature Key passphrase
[I thought about doing the following, but then decided against it; if I forget the passphrase or am incapacitated, that's too bad, but not actually that important in the grand scheme of things.]
I will encrypt the Master Signature Key using a reasonably strong passphrase containing upper- and lower-case letters, numbers, and symbols.
This passphrase is encrypted with the public keys of two trusted friends, and placed on CDs in both secure locations. The encrypted passphrases may be printed as well. This guards against the possibility that I forget the passphrase (or am incapacitated, etc.); in that case, a trusted friend accessing one secure location can retrieve the passphrase, as well as the master private key itself. The passphrase is not recorded anywhere else; it exists only in my memory and in these encrypted forms.
]]>My Master Signature Key is used only for signing keys and collecting signatures. If you wish to sign my key, please use this one. Please verify the fingerprint with me in person before signing it, of course.
pub 4096R/D8D9E1FD 2008-11-09
uid David Alexander Wolfgang Soergel (Master Signing Key - http://www.davidsoergel.com/gpg.html) david@davidsoergel.com
This is my Daily Use Key, to which emails should be encrypted, and with which emails from me will be signed:
pub 2048R/6BD15591 2008-11-09 [expires: 2011-11-09]
uid David Soergel (http://www.davidsoergel.com/gpg.html) lorax@lorax.org
Because my Daily Use Key is signed with my Master Signature Key, it is not necessary or useful for anyone else to sign it directly. Just import both of the keys, update your trustdb, and all should be well.
I am retiring my old key, 33F6A473; it will expire at the end of 2008.
The design requirements were:
- Occasional full backups, and daily incremental backups
- Stream data to S3, rather than making a local temp file first (i.e., if I want to archive all of /home at once, there's no point in making huge local tarball, doing lots of disk access in the process)
- Break up large archives into manageable chunks
- Encryption
As far as I could tell, no available backup script (including, e.g. s3sync, backup-manager, s3backup, etc. etc.) met all four requirements.
The closest thing is js3tream, which handles streaming and splitting, but not incrementalness or encryption. Those are both fairly easy to add, though, using tar and gpg, as suggested by the js3tream author. However, the s3backup.sh script he provides uses temp files (unnecessarily), and does not encrypt. So I modified it a bit to produce s3backup-gpg-streaming.sh.
That's not the end of the story, though, since it leaves open the problem of managing the backup rotation. I found the explicit cron jobs suggested on the js3tream site too messy, especially since I sometimes want to back up a lot of different directories. Some other available solutions will send incremental backups to S3, but never purge the old ones, and so use ever more storage.
Finally, I wanted to easily deal with MySQL and Subversion dumps.
The solution
I wrote s3napback, which wraps js3tream and solves all of the above issues by providing:
- Dead-simple configuration
- Automatic rotation of backup sets
- Alternation of full and incremental backups (using "tar -g")
- Integrated GPG encryption
- No temporary files used anywhere, only pipes and TCP streams (optionally, uses smallish temp files to save memory)
- Integrated handling of MySQL dumps
- Integrated handling of Subversion repositories, and of directories containing multiple Subversion repositories.
It's not rocket science, just a wrapper that makes things a bit easier.
Check out the project page for more info and to download it!
]]>