
Confirmation Depth as a measure of reproducible scientific research.
In striving for reproducible science, we need to be very clear on what it actually means to reproduce a result. The concept of confirmation depth helps to describe which possible sources of error in the original study have been eliminated in the reproduction.
Science needs fixing.
Many recent reports that scientific results are not reproducible (Ioannidis, 2005-2014; RetractionWatch) make it all too easy too reach the cynical conclusion that nearly every reported result is wrong. Sam Ruhmkorff calls this the “global pessimistic meta-induction”, but argues that this level of cynicism is overly broad, when most individual experiences justify only a “local pessimistic meta-induction”, e.g. that the scientific results in a particular field or produced by certain researchers are probably wrong. Let us hope he is right that science as a whole is not doomed.
Note on vocabulary: many scientists make a distinction between "replication" (e.g., same experimental conditions) and "reproduction" (e.g., different conditions, same conclusion), but other scientists make the opposite distinction. Here we give up and use the terms interchangeably.
What is a scientific result?
Precision. In order to know whether a result has been reproduced, it is essential first to state very precisely what the result actually is. Frequently two papers make similar-sounding claims about the same general topic, leading readers to believe that a result has been confirmed--when in fact, upon closer examination, the claims are qualitatively and quantitatively different.
Abstraction. Related: authors very frequently make far broader claims than their specific findings justify--not only in the discussion, but even in the abstract and the title. Following on publication of some result, another paper may lend support to the same general claim on the basis of different specific findings. In such a case, the exact experiment was not reproduced, but the general conclusion may have become more credible through multiple lines of evidence. It would overstate the case to say it has been “reproduced”, since two experimental conditions are likely insufficient to prove a more general point even once. The more abstract the claim, the more diverse evidence is needed to establish it.
It is common to describe these things using ambiguous language, e.g. “we reproduced the results of Gryphon et al. 2009”. Which results, exactly? At what level of abstraction? To what extent were the experimental design, materials, and methods shared between the two studies?
Levels of reproduction and confirmation depth
The point of reproducing a study is to eliminate possible sources of error. However: if a reproduction is subject to the same sources of error present in the original study, then it clearly does not fulfill this purpose, and so may serve only to provide a false sense of security.
We must therefore ask: if the first paper to report a result contains an error, is there any pathway whereby that error might propagate to a second paper reporting the same result? People may say “multiple lines of evidence”, which of course sounds good, but was the underlying sample the same? Was the work done in the same lab? Was the same software used?
Robust results require different experimental conditions.
In fact the most convincing reproduction of a result is one in which every aspect of the protocol was different, but the result was the same--indicating that it is robust. Differences we may look for and celebrate include:
- Different data sources (e.g. samples)
- Different researchers
- Different laboratory
- Different hardware
- Different firmware (e.g. In sequencing machines -> affects error profile. In cameras -> affects color profile)
- Different software
- Different workflow system (?)
- Different thought process/experimental design (perhaps undermined by knowledge of prior paper).
Only at the final step--interpreting the results--is it essential that all parties agree on something, namely that the experimental design, data, and analysis in fact support the claimed conclusions. This is of course what peer review is intended to verify.
Drawing derivation networks allows measuring confirmation depth.
Any research project can be thought of as a series of derivations, starting from raw inputs, proceeding through intermediate results (e.g. processed samples, data files), and ultimately producing not only a final quantitative result but also interpretations, all encapsulated in a published work.
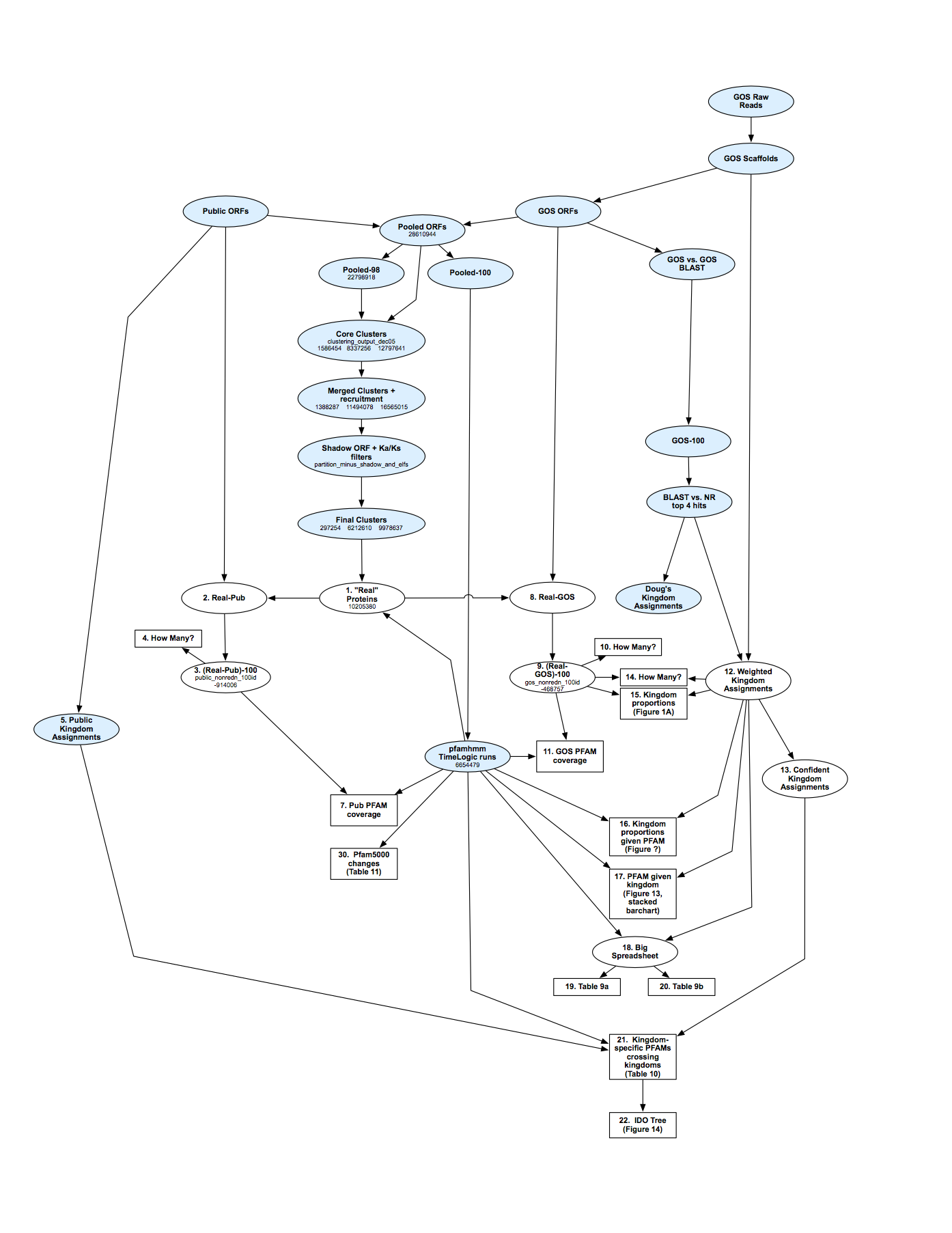
Figure 1. Any scientific result arises from a network of derivations, leading from raw inputs (e.g., measurements, source code), through intermediate results, to outputs. This example shows the computational portion of such a network (neglecting e.g. experimental design and sample collection, starting from raw sequencing reads in the upper right), which produced the results of Craig Venter's Global Ocean Survey project (Yooseph et al. 2007).
At whatever point in this series of derivations an error occurs, it renders useless all the work that came before--i.e., if there is a software bug late in the game, then all bets are off as to what was in the sample.
This suggests the concept of confirmation depth: given two papers with the same result, how many steps back from that result is the first commonality of materials or methods found? Conversely, how derived are the givens shared by the two papers?
Of course, a certain level of replication is required within a paper as well. Here the same principle applies: in biology, researchers speak of “biological replicates” (different samples) as more meaningful than “technical replicates” (repeated analyses from the same sample). Those are two points on a continuum of confirmation depth.
Peer review is the shallowest form of confirmation.
Peer review asks: given that the experiment has already been designed, the samples collected, the data analyzed, etc., does the conclusion make sense? That is, we ask peer reviewers to reproduce the thought process leading from the data to the qualitative conclusions (which is effectively the final step in the derivation), in order to confirm that the argument is cogent.
A particularly dedicated peer reviewer might recompute some result from provided data files, perhaps using the same software or the same methods. Doing so “peels” the confirmation away from the original result, and thereby increases the confirmation depth by one step.
Deeper confirmations give greater confidence.
Deeper confirmations may be performed by other researchers, peeling back the confirmation by any number of additional steps. Some may reanalyze the published data using different software or different statistical methods; others may request physical samples to be mailed for independent measurements, followed by analysis with different software; others may go so far as to collect entirely new samples and to analyze them by a completely different procedure. The deeper the confirmation, the more confidence we will have in the result. Conversely: the shallower any attempt that produces a failure to confirm, the less confidence we will have in either the original or the new result.
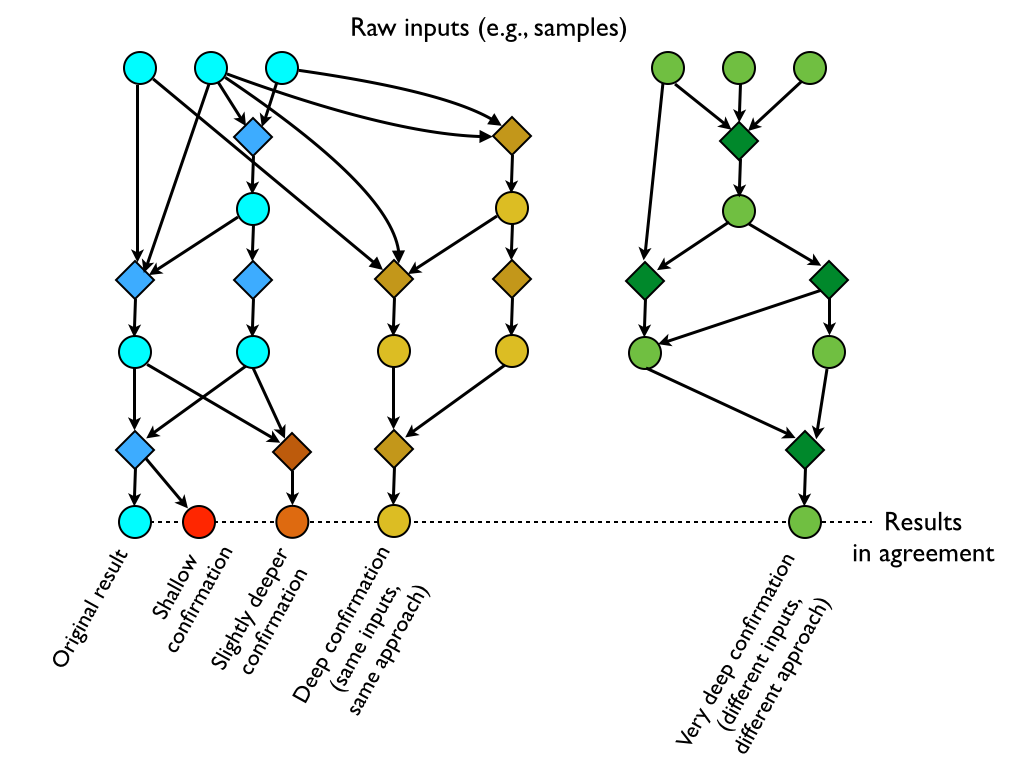
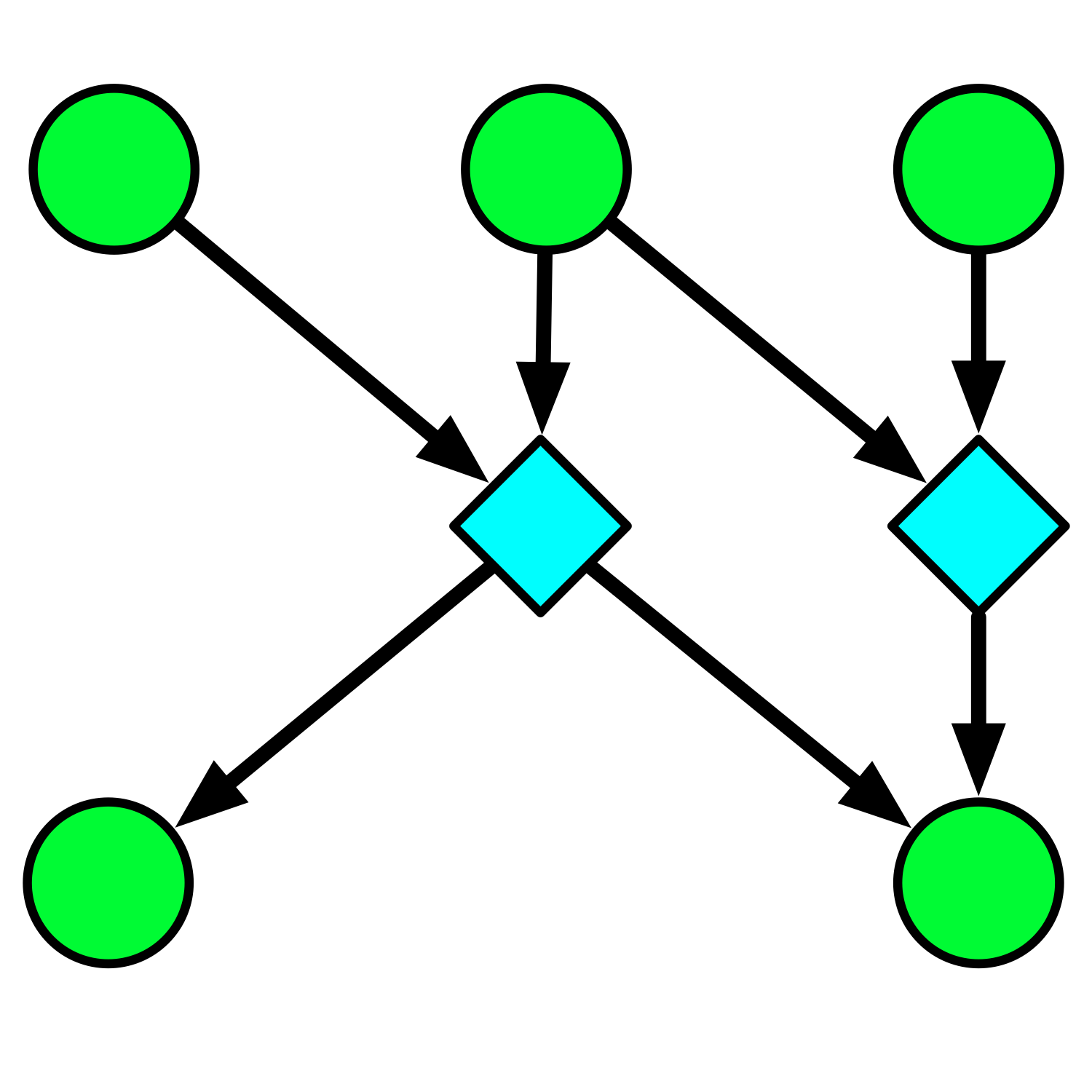
Figure 2. Attempts to reproduce a final result may start from intermediate results of the original project. The more diverged the chain of derivations, the fewer opportunities for error the two efforts have in common--and so, the more confidence we may have that the result was meaningfully reproduced.
Shallow commonalities trump deep differences as sources of error.
The idea of confirmation depth points out a real danger: a well-intentioned attempt to reproduce a result deeply--using different samples, processing them in a different lab, etc.--may nonetheless be undermined by late-stage sources of error. Using the same software (with the same bug), or using the same statistical method (with the same weakness), may spuriously produce the same result. Consequently, shallow commonalities should trump deep differences in reducing our trust in the outcome, unless we have extremely high confidence that the common elements cannot be a source of error.
Naturally we are happiest when we get the same result from a large number of experiments having nothing whatsoever in common--as is the case for our foundational beliefs about gravity, evolution, climate change, and so on.
Detailed materials and methods are essential to distinguish shallow from deep confirmations.
No confirmation is possible without extremely precise descriptions of materials and methods. The point is not that the reproducing lab should necessarily follow the original protocol exactly, as doing so would in fact reduce the confirmation depth; rather, the reproducing lab may wish to purposely follow a different procedure, or use reagents from different sources, in order to eliminate (or at least average over) possible sources of error. Perhaps-inadvertent commonalities between two protocols can only be known if they are both spelled out in meticulous detail. On the other hand, it is wise to perform confirmations progressively from shallow to deep. If even following the exact protocol with the exact same materials does not produce the same result, then there is no point in seeking a deeper confirmation-- at least, not of the specific finding.
A converse danger is that, the more deeply diverged two experiments are from one another, the less likely they are to produce results that are comparable at all. This is why it is necessary to state very precisely what claims are being made. Such claims may be made at multiple levels of generality, so that two studies may support the same broad claim while differing in the specifics. The ideal case we seek for a thorough confirmation is that exactly the same result (at some appropriate level of abstraction) was produced from completely different materials and methods. We can only know whether (or to what extent) this criterion is met when studies report their materials, methods, and results in concise, detailed, and comparable forms.